

Lucene 是apache软件基金会一个开放源代码的全文检索引擎工具包,是一个全文检索引擎的架构,提供了完整的查询引擎和索引引擎,部分文本分析引擎。Lucene的目的是为软件开发人员提供一个简单易用的工具包,以方便的在目标系统中实现全文检索的功能,或者是以此为基础建立起完整的全文检索引擎。
Lucene最初是由Doug Cutting所撰写的,是一位资深全文索引/检索专家,曾经是V-Twin搜索引擎的主要开发者,后来在Excite担任高级系统架构设计师,目前从事 于一些INTERNET底层架构的研究。他贡献出Lucene的目标是为各种中小型应用程式加入全文检索功能。
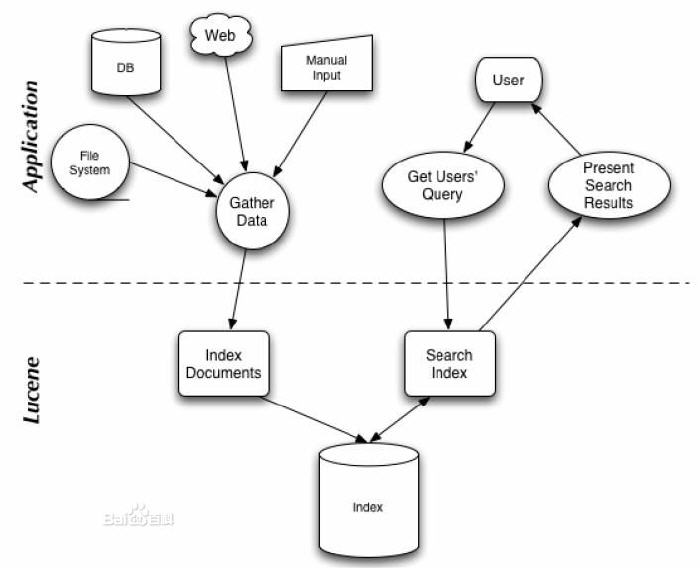
功能特色
Lucene是一个高性能、可伸缩的信息搜索(IR)库。它可以为你的应用程序添加索引和搜索能力。Lucene是用java实现的、成熟的开源项目,是著名的Apache Jakarta大家庭的一员,并且基于Apache软件许可 [ASF, License]。同样,Lucene是
当前非常流行的、免费的Java信息搜索(IR)库。
突出的优点
Lucene作为一个全文检索引擎,其具有如下突出的优点:
(1)索引文件格式独立于应用平台。Lucene定义了一套以8位字节为基础的索引文件格式,使得兼容系统或者不同平台的应用能够共享建立的索引文件。
(2)在传统全文检索引擎的倒排索引的基础上,实现了分块索引,能够针对新的文件建立小文件索引,提升索引速度。然后通过与原有索引的合并,达到优化的目的。
(3)优秀的面向对象的系统架构,使得对于Lucene扩展的学习难度降低,方便扩充新功能。
(4)设计了独立于语言和文件格式的文本分析接口,索引器通过接受Token流完成索引文件的创立,用户扩展新的语言和文件格式,只需要实现文本分析的接口。
(5)已经默认实现了一套强大的查询引擎,用户无需自己编写代码即使系统可获得强大的查询能力,Lucene的查询实现中默认实现了布尔操作、模糊查询(Fuzzy Search)、分组查询等等。
首先,它的开发源代码发行方式(遵守Apache Software License),在此基础上程序员不仅仅可以充分的利用Lucene所提供的强大功能,而且可以深入细致的学习到全文检索引擎制作技术和面向对象编程的实践,进而在此基础上根据应用的
实际情况编写出更好的更适合当前应用的全文检索引擎。
其次,Lucene秉承了开放源代码一贯的架构优良的优势,设计了一个合理而极具扩充能力的面向对象架构,程序员可以在Lucene的基础上扩充各种功能,比如扩充中文处理能力,从文本扩充到HTML、PDF等等文本格式的处理,编写这些扩展
的功能不仅仅不复杂,而且由于Lucene恰当合理的对系统设备做了程序上的抽象,扩展的功能也能轻易的达到跨平台的能力。
转移到apache软件基金会后,借助于apache软件基金会的网络平台,程序员可以方便的和开发者、其它程序员交流,促成资源的共享,甚至直接获得已经编写完备的扩充功能。最后,虽然Lucene使用Java语言写成,但是开放源代码社区的程
序员正在不懈的将之使用各种传统语言实现(例如.net framework),在遵守Lucene索引文件格式的基础上,使得Lucene能够运行在各种各样的平台上,系统管理员可以根据当前的平台适合的语言来合理的选择。
特别说明
lucene有7个包需要导入:analysis,document,index,queryParser,search,store,util
∨ 展开
 highlight代码高亮
highlight代码高亮 Scylla
Scylla RoboDK
RoboDK AutoFlowchart
AutoFlowchart 滑稽编程助手
滑稽编程助手 Java SE Runtime Environment 7.0
Java SE Runtime Environment 7.0 GX Works2 仿真软件
GX Works2 仿真软件 Visual Assist X vs2017 破解
Visual Assist X vs2017 破解 visual assist 2013免注册
visual assist 2013免注册 PC Logo电脑版
PC Logo电脑版 SonarLint Eclipse
SonarLint Eclipse PostScript软件
PostScript软件 MKScript脚本解释器
MKScript脚本解释器 MKScript绿色版
MKScript绿色版 Sublime Text4中文版
Sublime Text4中文版 PeStudio
PeStudio PilotEdit 中文破解
PilotEdit 中文破解 PeStudio中文版
PeStudio中文版 MKScript(鼠标键盘自动化脚本解释器)
MKScript(鼠标键盘自动化脚本解释器) TortoiseSVN 64位
TortoiseSVN 64位

 CopperCube(3D游戏引擎)
CopperCube(3D游戏引擎) skycc搜索引擎收录与权重批量查询工具
skycc搜索引擎收录与权重批量查询工具 PhysicsEditor(物理引擎编辑器)
PhysicsEditor(物理引擎编辑器) Starling(附教程)
Starling(附教程) Egret Engine (html5 app开发)
Egret Engine (html5 app开发) Egret Conversion (HTML5游戏引擎)
Egret Conversion (HTML5游戏引擎) Cygwin(unix模拟环境) 1.7.3 最新版
Cygwin(unix模拟环境) 1.7.3 最新版 ThinkPHP(PHP开发框架) 3.1.3 完整版
ThinkPHP(PHP开发框架) 3.1.3 完整版 RStudio中文版 1.1.383 桌面版
RStudio中文版 1.1.383 桌面版 Spring框架 4.3.12 正式版
Spring框架 4.3.12 正式版 Spring Framework J2EE框架 4.3.12 正式版
Spring Framework J2EE框架 4.3.12 正式版 Visual Studio 2012 Ultimate 简体中文旗舰版
Visual Studio 2012 Ultimate 简体中文旗舰版 winhex专业单文件版 18.7 SR-2 汉化破解
winhex专业单文件版 18.7 SR-2 汉化破解 TinyMCE编辑器 4.1.5 中文
TinyMCE编辑器 4.1.5 中文 xml文件编辑器 2.2 绿色免费版
xml文件编辑器 2.2 绿色免费版 Microsoft Windows SDK 7.1 最新版
Microsoft Windows SDK 7.1 最新版