
Apache Flink 是一个开源的流处理框架,应用于分布式、高性能、始终可用的、准确的数据流应用程序。Apache Flink新版本继续围绕使用户能够无缝地运行快速数据处理并轻松构建数据驱动和数据密集型应用而改进,让用户可以更好进行数据处理。
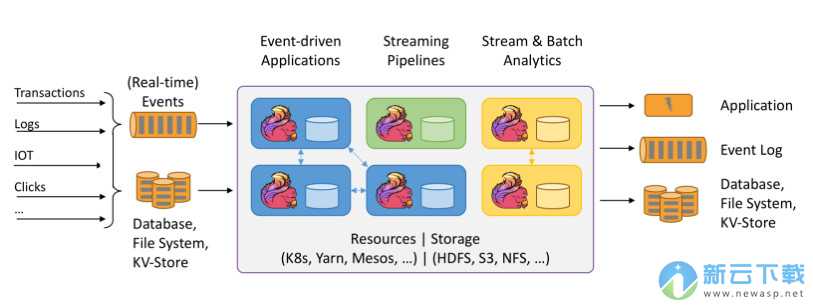
Apache Flink 特点
处理无界和有界数据
任何类型的数据都是作为事件流产生的。信用卡交易,传感器测量,机器日志或网站或移动应用程序上的用户交互,所有这些数据都作为流生成。
随处部署应用程序
Apache Flink是一个分布式系统,需要计算资源才能执行应用程序。Flink与所有常见的集群资源管理器(如Hadoop YARN,Apache Mesos和Kubernetes)集成,但也可以设置为作为独立集群运行。
以任何比例运行应用程序
Flink旨在以任何规模运行有状态流应用程序。应用程序可以并行化为数千个在集群中分布和同时执行的任务。因此,应用程序可以利用几乎无限量的CPU,主内存,磁盘和网络IO。而且,Flink可以轻松维护非常大的应用程序状态。其异步和增量检查点算法确保对处理延迟的影响最小,同时保证一次性状态一致性。
利用内存中的性能
有状态Flink应用程序针对本地状态访问进行了优化。任务状态始终保留在内存中,或者,如果状态大小超过可用内存,则保存在访问高效的磁盘上数据结构中。因此,任务通过访问本地(通常是内存中)状态来执行所有计算,从而产生非常低的处理延迟。Flink通过定期和异步检查本地状态到持久存储来保证在出现故障时的一次状态一致性。
更新日志
新增对 state TTL 的原生支持。此功能允许在 state 到期后进行清理;
继续完善 1.5.0 重构的 Flink 分布式架构,并简化容器设置;
进一步改进 SQL CLI,使得针对大量数据源执行流式处理和批处理查询更容易;
新增 StreamingFileSink ,以及对 ElasticSearch 6.x 的支持;
优化 Timer Deletions 。
安装教程
下载并启动Flink
Flink可在Linux,Mac OS X和Windows上运行。为了能够运行Flink,唯一的要求是安装一个有效的Java 8.x. Windows用户。
您可以通过发出以下命令来检查Java的正确安装:
java -version
如果你有Java 8,输出将如下所示:
java version "1.8.0_111"
Java(TM) SE Runtime Environment (build 1.8.0_111-b14)
Java HotSpot(TM) 64-Bit Server VM (build 25.111-b14, mixed mode)
下载并解压缩
1、从下载页面下载二进制文件。您可以选择任何您喜欢的Hadoop / Scala组合。如果您打算只使用本地文件系统,任何Hadoop版本都可以正常工作。
2、转到下载目录。
3、解压缩下载的存档。
$ cd ~/Downloads # Go to download directory
$ tar xzf flink-*.tgz # Unpack the downloaded archive
$ cd flink-1.6.0
启动本地Flink群集
$ ./bin/start-cluster.sh # Start Flink
∨ 展开
 highlight代码高亮
highlight代码高亮 Scylla
Scylla RoboDK
RoboDK AutoFlowchart
AutoFlowchart 滑稽编程助手
滑稽编程助手 Java SE Runtime Environment 7.0
Java SE Runtime Environment 7.0 GX Works2 仿真软件
GX Works2 仿真软件 Visual Assist X vs2017 破解
Visual Assist X vs2017 破解 visual assist 2013免注册
visual assist 2013免注册 PC Logo电脑版
PC Logo电脑版 SonarLint Eclipse
SonarLint Eclipse PostScript软件
PostScript软件 MKScript脚本解释器
MKScript脚本解释器 MKScript绿色版
MKScript绿色版 Sublime Text4中文版
Sublime Text4中文版 PeStudio
PeStudio PilotEdit 中文破解
PilotEdit 中文破解 PeStudio中文版
PeStudio中文版 MKScript(鼠标键盘自动化脚本解释器)
MKScript(鼠标键盘自动化脚本解释器) TortoiseSVN 64位
TortoiseSVN 64位

 IDE开发工具(Egret Wing)
IDE开发工具(Egret Wing) InnoIDE编辑工具
InnoIDE编辑工具 aardio快手
aardio快手 IAR for RL78 破解
IAR for RL78 破解 Mathematica 11.2 破解
Mathematica 11.2 破解 Faux Pas for Xcode
Faux Pas for Xcode PHPMaker 2018 中文版
PHPMaker 2018 中文版 Longtion RadBuilder
Longtion RadBuilder Cygwin(unix模拟环境) 1.7.3 最新版
Cygwin(unix模拟环境) 1.7.3 最新版 ThinkPHP(PHP开发框架) 3.1.3 完整版
ThinkPHP(PHP开发框架) 3.1.3 完整版 RStudio中文版 1.1.383 桌面版
RStudio中文版 1.1.383 桌面版 Spring框架 4.3.12 正式版
Spring框架 4.3.12 正式版 Spring Framework J2EE框架 4.3.12 正式版
Spring Framework J2EE框架 4.3.12 正式版 Visual Studio 2012 Ultimate 简体中文旗舰版
Visual Studio 2012 Ultimate 简体中文旗舰版 winhex专业单文件版 18.7 SR-2 汉化破解
winhex专业单文件版 18.7 SR-2 汉化破解 TinyMCE编辑器 4.1.5 中文
TinyMCE编辑器 4.1.5 中文 xml文件编辑器 2.2 绿色免费版
xml文件编辑器 2.2 绿色免费版 Microsoft Windows SDK 7.1 最新版
Microsoft Windows SDK 7.1 最新版