
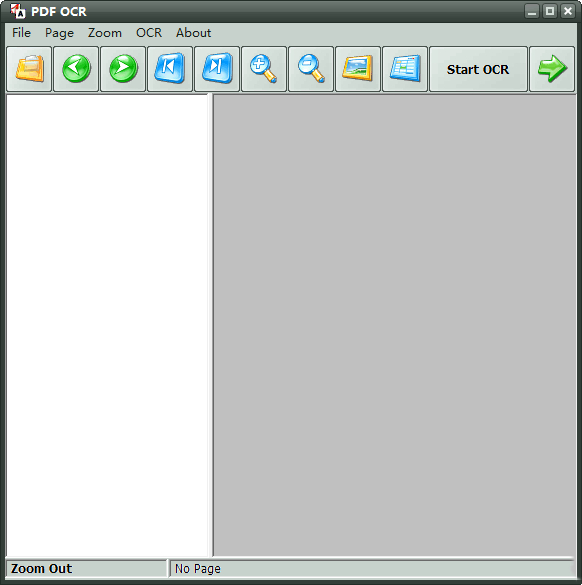
PDF OCR是一款优秀的PDF识别工具,能够快速的识别PDF文件中的文字部分,并加以提取导出,轻松解决某些PDF文件无法编辑的问题,除此之外软件还支持其他关于PDF文件的编辑功能,需要经常编辑PDF文件的小伙伴们完全可以来下载这款软件使用,觉得不错就来下载体验吧!
软件特色
1、基于强大的OCR识别技术,可以识别图像或者PDF纸质文档中的内容。
2、可以高效的从PDF文档中识别出文字并导出保存为文本。
3、还可以直接在图片中识别图片中的文字,然后将其转换为PDF。
4、高效的转换速度,可以帮助用户高效的完成PDF文档的编辑工作。
5、内置纹文本编辑工具,识别完成之后可以直接在该编辑器中编辑文本。
6、可让您在不使用MS Word的情况下编辑ocr结果文本。
7、用户可以自定义选择需要识别的PDF页码,可以自定义选择多个页面进行批量识别。
8、如果您有多个PDF文件页面,则可以立即将它们转换为可编辑的文本文件。
9、如果您需要创建一本电子数据,那么使用这款工具提取PDF中的内容是非常好的。
10、用户将扫描的PDF文件转换为可编辑的电子文件后,可以继续在软件中进行更正。
11、您可以对A4,A3,B3,B4,B5和其他类型的PDF扫描页进行OCR。
软件功能
1.将扫描后的PDF转换为文本
PDF OCR将扫描后的PDF转换为文本,然后您可以编辑或使用PDF内容。
2.支持所有页面大小
PDF OCR支持A4、A3、B3、B4、B5等所有扫描页面大小。
3.将扫描图像转换为PDF文档
PDF OCR将扫描图像转换为PDF文档,并创建扫描PDF文档。
4.易于使用
PDF OCR只需要点击3下将PDF转换为文本。
5.OCR PDF快
PDF OCR将在45秒内处理超过10页。
6.内置文本编辑器
PDF OCR有一个内置的文本编辑器,允许您在没有MS Word或WordPad的情况下编辑OCR结果文本。
7.拥有3种PDF OCR模式
支持对单页、整页或者自定义页面进行OCR
常见问题
什么是PDF OCR,我该怎么办?
PDF OCR基于OCR技术,可将扫描的PDF纸质书和文档快速,轻松地转换为可编辑的电子文本文件。PDF OCR具有内置的文本编辑器,可让您在不使用MS Word的情况下编辑ocr结果文本。PDF OCR还支持批处理模式,一次将所有pdf文件的页面OCR转换为文本。
PDF OCR的系统要求是什么?
Microsoft Windows XP,Windows Vista,Windows 7,Windows 2003,Windows 2000或Windows ME。
奔腾处理器或更高,推荐奔腾4或更高。
128MB RAM或更多,建议使用256MB RAM。
20MB用于安装的硬盘空间。
为什么结果与原始PDF文档不完全相同?
PDF OCR使用光学字符识别技术,该技术可识别图片和图像中的文本,可识别率取决于PDF文本字体,背景和许多因素。因此,PDF OCR无法识别100%正确的文本,但我们仍在努力改善程序。
为什么在结果文本中出现许多未知字符?
PDF OCR只能识别PDF文件中的文本,并且图像和图形也将被识别为文本,因此您可能会得到未知字符。您可以在文本编辑器中删除未知字符。
∨ 展开
 WPS Office 2023 教育版
WPS Office 2023 教育版 Typora windows安装
Typora windows安装 WPS Office 2019专业增强版
WPS Office 2019专业增强版 Microsoft Office软件
Microsoft Office软件 Microsoft Office专业增强版
Microsoft Office专业增强版 Microsoft Office2024
Microsoft Office2024 Rogabet Notepad老罗笔记
Rogabet Notepad老罗笔记 幂果OCR文字识别2024
幂果OCR文字识别2024 金山协作
金山协作 onlyoffice电脑版
onlyoffice电脑版 鱼鱼多媒体日记本
鱼鱼多媒体日记本 论文抽屉免费版
论文抽屉免费版 牛牛排版4.0
牛牛排版4.0 蓝牛复制粘贴助手
蓝牛复制粘贴助手 SushiHelper最新版
SushiHelper最新版 Skylark编辑器
Skylark编辑器 防和谐文字处理器电脑版
防和谐文字处理器电脑版 梵语巴利语输入法
梵语巴利语输入法 快贴Mac版
快贴Mac版 快贴云剪贴板
快贴云剪贴板








 OCR识别软件
OCR识别软件 Procreate Pocket APP
Procreate Pocket APP OCR识别大师
OCR识别大师 白描OCR文字识别
白描OCR文字识别 OCR文字识别助手2023
OCR文字识别助手2023 全能王ocr扫描王
全能王ocr扫描王 OCR图片文字识别
OCR图片文字识别 OCR工具集
OCR工具集 英文识别软件
英文识别软件 智速OCR识别软件
智速OCR识别软件 迅捷OCR文字识别软件
迅捷OCR文字识别软件 eSearch图像识别软件便携版
eSearch图像识别软件便携版 一键扫描识别软件安卓版
一键扫描识别软件安卓版 万物识别软件
万物识别软件 闪电OCR图片文字识别软件
闪电OCR图片文字识别软件 智能拍照识别
智能拍照识别 OCR文字识别软件
OCR文字识别软件 ABBYY FineReader 12中文专业版
ABBYY FineReader 12中文专业版 天若OCR文字识别本地版
天若OCR文字识别本地版 万兴PDF软件OCR组件离线安装包国际版
万兴PDF软件OCR组件离线安装包国际版 EasyScreenOCR
EasyScreenOCR PandaOCR破解
PandaOCR破解 易文档
易文档 图片转文字识别精灵
图片转文字识别精灵 灵鹿文字识别
灵鹿文字识别 白描
白描 极度扫描orc文字识别免费版
极度扫描orc文字识别免费版 得力ocr文字识别电脑版
得力ocr文字识别电脑版 思源笔记Mac版 2.9.9 官方最新版
思源笔记Mac版 2.9.9 官方最新版 腾讯文档电脑版 3.1.1 官方最新版
腾讯文档电脑版 3.1.1 官方最新版 子魚笔记Mac版 0.64.0 官方正式版
子魚笔记Mac版 0.64.0 官方正式版 黑曜石笔记软件 1.3.7 绿色中文版
黑曜石笔记软件 1.3.7 绿色中文版 橙瓜码字电脑版 3.0.7 最新版
橙瓜码字电脑版 3.0.7 最新版