


Sovits4.0是一款能够训练AI的智能软件,用户只需要将大量的语音素材“投喂”给AI到了一定程度就能实现“炼成”了!你就会得到一位基于素材的虚拟歌手,用户可以控制它演唱任何歌曲,但效果好坏就要看训练的成果了,感兴趣的朋友们快来下载试用吧!
使用说明
为避免可能的法律纠纷和道德风险,使用者在使用该整合包前,请务必仔细阅读本条款,继续使用即代表理解并同意该声明,如有异议,请立即停止使用并删除本整合包。
1. 本整合包修改自So-VITS-SVC 4.0项目,该项目目前由So-VITS社区维护。
2. 在使用本整合包时,必须根据知情同意原则取得数据集音声来源的授权许可,并根据授权协议条款规定使用数据集。
3. 禁止使用该整合包对公众人物、政治人物或其他容易引起争议的人物进行模型训练。使用本整合包产出和传输的信息需符合中国法律、国际公约的规定、符合公序良俗。不将本整合包以及与之相关的服务用作非法用途以及非正当用途。
4. 禁止将本整合包用于血腥、暴力、性相关、或侵犯他人合法权利的用途。
5. 任何发布到视频平台的基于So-VITS制作的视频,都必须要在简介明确指明用于变声器转换的输入源歌声、音频,例如:使用他人发布的视频/音频,通过分离的人声作为输入源进行转换的,必须要给出明确的原视频、音乐链接;若使用是自己的人声,或是使用其他歌声合成引擎合成的声音作为输入源进行转换的,也必须在简介加以说明。
软件使用
简单总结一下推理的过程
1、下载模型(xxx.pth)到logs/44k目录下
2、下载模型配置(xxx.config)到configs目录下
3、运行webui(python app.py),并访问localhost:7860
4、选择模型和配置,并点击加载模型
5、加载成功后,准备干净的语音,使用UVW分离,获得干净语音(vocals)6、上传到webui上,并且点击推理进行推断7、使用audition进行合成(转换后的语音与伴奏)
其他链接参考
基底模型: https://huggingface.co/kingple/sovits4/tree/main wav
文件转换: https://www.aconvert.com/cn/audio/mp3-to-wav
VisualStudio安装器: https://visualstudio.microsoft.com/downloads Anaconda: https://www.anaconda.com pytorch: https://pytorch.org/get-started/locally/#windows-pip hubert
∨ 展开
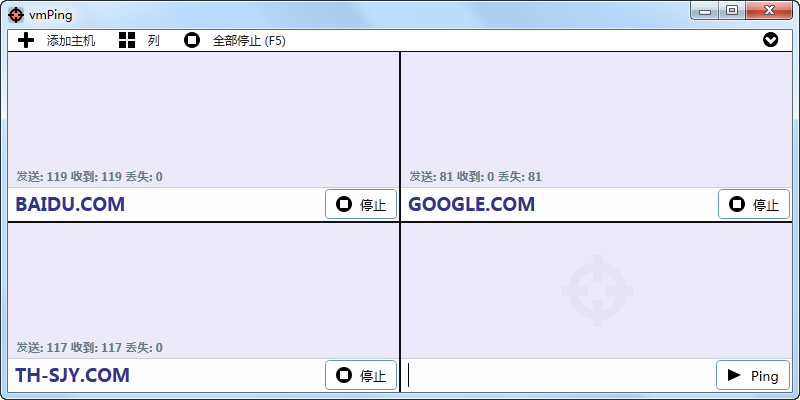 图形化 Ping 工具(vmPing)
图形化 Ping 工具(vmPing) 不坑盒子插件
不坑盒子插件 金山PDF阅读器
金山PDF阅读器 抽奖之星电脑版
抽奖之星电脑版 PLuckyDraw抽奖软件
PLuckyDraw抽奖软件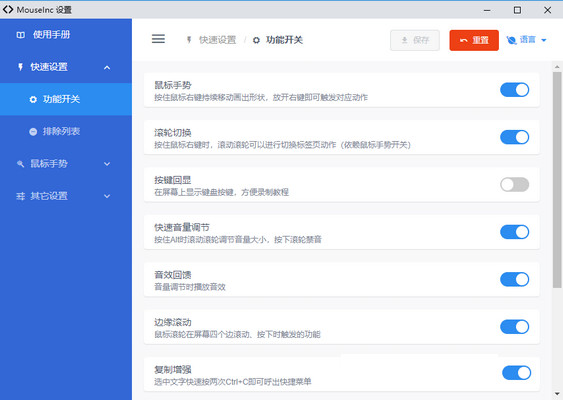 MouseInc插件
MouseInc插件 MoYu摸鱼
MoYu摸鱼 Excalibur计算器
Excalibur计算器 精编公司取名软件
精编公司取名软件 蓝光云挂机最新版
蓝光云挂机最新版 Taskade最新版
Taskade最新版 京喜工厂Tool
京喜工厂Tool 六六工具箱软件
六六工具箱软件 Loom软件
Loom软件 蓝砂智能称重系统
蓝砂智能称重系统 Epubor All DRM Removal
Epubor All DRM Removal Twinkle Tray亮度调节
Twinkle Tray亮度调节 鱼知凡工具箱最新版
鱼知凡工具箱最新版 微小宝Mac版
微小宝Mac版 微小宝电脑版
微小宝电脑版
 和平精英辅助
和平精英辅助 和平精英体验服
和平精英体验服 和平精英陀螺仪超频助手
和平精英陀螺仪超频助手 弱网和平精英
弱网和平精英 和平精英孙行者直装v2版
和平精英孙行者直装v2版 和平精英精简版
和平精英精简版 画质怪兽120帧和平精英
画质怪兽120帧和平精英 和平精英免费透视辅助
和平精英免费透视辅助 和平精英画质怪兽
和平精英画质怪兽 腾讯TIM
腾讯TIM 腾讯TIM
腾讯TIM 腾讯QQ2024
腾讯QQ2024 腾讯QQ for Mac
腾讯QQ for Mac 腾讯TIM电脑版
腾讯TIM电脑版 TIM电脑版防撤回精简版
TIM电脑版防撤回精简版 QQTim版
QQTim版 腾讯TIM精简版
腾讯TIM精简版 腾讯QQ体验版
腾讯QQ体验版 腾讯QQ软件合集
腾讯QQ软件合集 手机QQ安卓版
手机QQ安卓版 qq分身版
qq分身版 QQ办公版app
QQ办公版app QQ消息轰炸手机版2024
QQ消息轰炸手机版2024 qq极速版官方版
qq极速版官方版 QQ邮箱
QQ邮箱 qq手机版
qq手机版 qq精简版永不升级旧版本
qq精简版永不升级旧版本 腾讯软件中心
腾讯软件中心 腾讯文档电脑版
腾讯文档电脑版 腾讯会议电脑版
腾讯会议电脑版 腾讯手机管家电脑版
腾讯手机管家电脑版 腾讯视频电脑版
腾讯视频电脑版 腾讯视频纯净无广告版
腾讯视频纯净无广告版 腾讯视频
腾讯视频 幕布电脑版 3.7.0 官方版
幕布电脑版 3.7.0 官方版 cencrack在线工具包最新版 6.48 绿色中文版
cencrack在线工具包最新版 6.48 绿色中文版 RM Toolbox 8.4 最新版
RM Toolbox 8.4 最新版 癞蛤蟆工具箱PC版 4.0.0.7 最新版
癞蛤蟆工具箱PC版 4.0.0.7 最新版 BatteryInfoView 1.23 绿色版
BatteryInfoView 1.23 绿色版 Office Tool Plus 2020激活版 10.0.4.11 绿色版
Office Tool Plus 2020激活版 10.0.4.11 绿色版 淘宝助理天猫客户端 5.3.6 官方版
淘宝助理天猫客户端 5.3.6 官方版 极品时刻表12306电脑版 9.2.1 官方版
极品时刻表12306电脑版 9.2.1 官方版 考勤表 2022 Word版
考勤表 2022 Word版 12306Bypass 1.14.58 绿色版
12306Bypass 1.14.58 绿色版