
来自论坛用户原创制作分享的一款小说爬取工具,由Python编写,同时附上了源码资源方便大家浏览。笔趣阁小说爬取工具可以免费爬取下载网站小说资源,让您轻松获取想看的小说。使用前请参考相关说明,避免出现错误。
软件简介
笔趣阁小说爬取工具【附源码】可以免费下载笔趣阁小说网的所有内容,只需要找到喜欢的小说目录页链接,在工具操作界面按要求填写,就可以单线程下载每一章内容,并将它们全部汇总为一个文本文件,非常方便。
使用方法
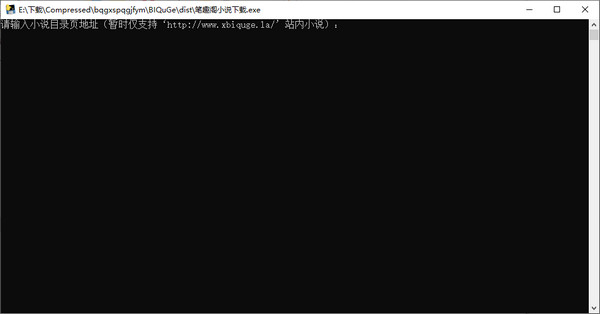
程序运行方法:解压,在本文件夹中找到并打开dist文件夹,有一个“笔趣阁小说下载.exe”,双击运行
1、前往笔趣阁网站,找到要保存的小说,复制那个小说的目录页链接
2、按要求输入链接地址和小说名
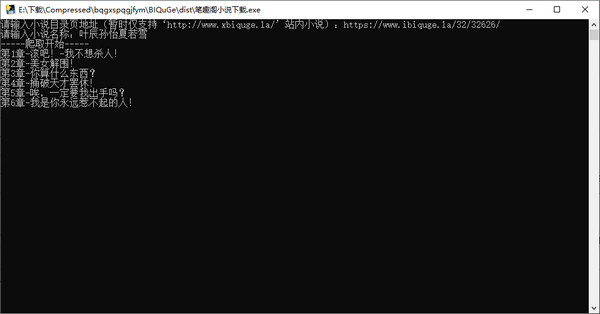
3、爬取开始
(因为是单线程运行,爬取速度略慢大概1-2秒一章)
4、爬取结束后,会将所有章节内容整合成一个txt文件
工具源码
import requests
import re
header = {
'User-Agent':'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.97 Safari/537.36'
}
#定义全局变量,用于保存所有获取到的小说内容
story_all = []
#获取标题及章节链接地址
def main():
url = input("请输入小说目录页地址(暂时仅支持‘http://www.xbiquge.la/’站内小说):")
book_name = input("请输入小说名称:")
print("-----爬取开始-----")
#获取目录页的HTML文本
text = requests.get(url,header).content.decode('utf-8')
#获取每个章节的章节名
title = re.findall(r'
.*?
(.*?)',text,re.DOTALL)
#获取每个章节的链接地址
loca = re.findall(r"
.*?='(.*?)' >",text,re.DOTALL)
#因为title和loca的长度相同,所以以索引的方式遍历,方便取值
for i in range(len(title)):
content(title,f'http://www.xbiquge.la{loca}')
#小说爬取完毕,开始保存
print("@"*500)
with open(r'%s.txt'%book_name, 'w',encoding='utf-8')as file:
#遍历每一项,按顺序保存章节名和章节内容
for story in story_all:
file.write(story['title']+' ')
print(story['title'])
file.write(story['story'])
#解析章节内容并保存
def content(title,url):
#获取章节页的HTML文本
text = requests.get(url,header).content.decode('utf-8')
#因为之前写过直接爬取所有内容的,爬取出来的文本都带有 不好处理
#所以就一句一句的获取了
story_content = re.findall(r' (.*?)
#因为章节名中有“”空格,没办法作为文件名,所以把空格去掉
title = re.sub(' ','-',title)
#有时候不知道为什么小说内容会爬取到一个空数组,所以这里添加了一个检测程序
#如果爬取到的为空,就重新爬取,直到获取到为止
if story_content==[]:
content(title,url)
return 0
story=""
#前面提到,因为我是一句一句爬取的,所以这里做一下拼接,顺便去空格
for story_contents in story_content:
story = story+story_contents.strip()+' '
#将章节名称和章节内容保存为一个字典
this_story = {
"title":title,
"story":story
}
print(this_story['title'])
#将字典添加到开头定义的全局变量中
story_all.append(this_story)
if __name__ == "__main__":
main()
∨ 展开
 Gopeed
Gopeed qBittorrent便携增强版
qBittorrent便携增强版 联想应用商店电脑版
联想应用商店电脑版 神奇网页图片下载
神奇网页图片下载 Apowersoft视频下载王PC版
Apowersoft视频下载王PC版 溜云库
溜云库 冰点文库2024
冰点文库2024 比特精灵BitSpirit中文免安装
比特精灵BitSpirit中文免安装 迅雷9
迅雷9 EagleGet猎鹰中文官方版
EagleGet猎鹰中文官方版 半次元无水印图片下载工具
半次元无水印图片下载工具 IDM下载器中文版
IDM下载器中文版 Internet Download Manager
Internet Download Manager 网商图片下载工具
网商图片下载工具 WebTorrent中文版
WebTorrent中文版 海康威视视频下载工具
海康威视视频下载工具 CRTubeGet视频下载器
CRTubeGet视频下载器 Gihosoft TubeGet Pro 最新版
Gihosoft TubeGet Pro 最新版 智慧中小学教材下载器
智慧中小学教材下载器 闪豆视频下载器
闪豆视频下载器




 无广告小说
无广告小说 艾克小说网
艾克小说网 大神小说
大神小说 格格党小说网手机阅读
格格党小说网手机阅读 山丘夜猫小说阅读器
山丘夜猫小说阅读器 全本免费小说免费版
全本免费小说免费版 连情小说
连情小说 一纸小说
一纸小说 4020电子书小说app
4020电子书小说app 小说免费阅读APP
小说免费阅读APP 常读小说免费版
常读小说免费版 宜搜小说免费版
宜搜小说免费版 全民小说免费版
全民小说免费版 追更小说免费版
追更小说免费版 即看小说免费版
即看小说免费版 点文小说免费版
点文小说免费版 悠悠小说免费版
悠悠小说免费版 轻小说阅读器
轻小说阅读器 菠萝包轻小说app
菠萝包轻小说app 必看免费小说app
必看免费小说app 动漫之家轻小说App
动漫之家轻小说App sf轻小说app
sf轻小说app 亲小说
亲小说 轻之国度
轻之国度 新笔趣阁手机版
新笔趣阁手机版 esj轻小说
esj轻小说 香蕉悦读(原米看小说)
香蕉悦读(原米看小说) EhPG小说下载器电脑版
EhPG小说下载器电脑版 全本免费小说阅读器电脑版
全本免费小说阅读器电脑版 小说下载阅读器PC版
小说下载阅读器PC版 KK小说阅读器
KK小说阅读器 智客小说
智客小说 uncle小说下载工具
uncle小说下载工具 Aiys小说下载器
Aiys小说下载器 IDM多线程下载器 6.41.16 绿色版(附注册机)
IDM多线程下载器 6.41.16 绿色版(附注册机) Ant Download Manager 专业版 2.10.3.86203 官方中文版
Ant Download Manager 专业版 2.10.3.86203 官方中文版 danmu tools 3.9.10 正式版
danmu tools 3.9.10 正式版 Antdownload2蚂蚁下载器二代 1.0.6 绿色版
Antdownload2蚂蚁下载器二代 1.0.6 绿色版 uTorrent Pro汉化版去广告版 3.6.0.46612 绿色版
uTorrent Pro汉化版去广告版 3.6.0.46612 绿色版 Apowersoft视频下载王 6.4.11 中文免费版
Apowersoft视频下载王 6.4.11 中文免费版 4K Video Downloader中文便携破解 4.22.0 绿色版
4K Video Downloader中文便携破解 4.22.0 绿色版 MusicTools无损音乐下载神器 1.9.7.6 正式版
MusicTools无损音乐下载神器 1.9.7.6 正式版