
WebMagic中文版是java上面经常的需要的一款爬虫类型的工具,现在就可以试试最新的0.7.3版本,功能以及使用上面都是完全的免费的,欢迎大家下载使用!
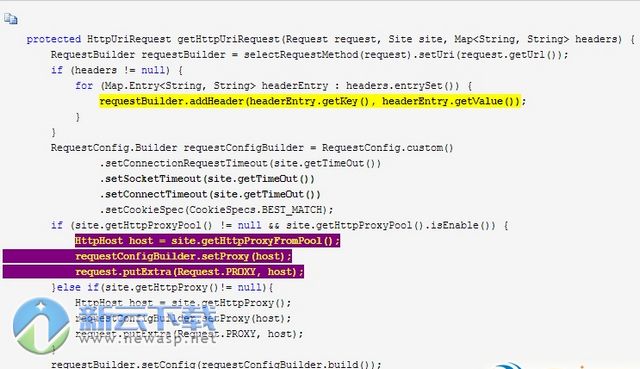
中文版功能
WebMagic是一个简单灵活的Java爬虫框架。基于WebMagic,你可以快速开发出一个高效、易维护的爬虫。webmagic采用完全模块化的设计,功能覆盖整个爬虫的生命周期(链接提取、页面下载、内容抽取、持久化),支持多线程抓取,分布式抓取,并支持自动重试、自定义UA/cookie等功能。
常见问题
(1)由于我这个爬虫的抓取有分页,而且它的分页通过js跳转的,抽取出来感觉有点麻烦,我想直接得到所有的信息,发现可以通过输入url地址请求得到所有的信息(这是网站的一个小问题,它没有设置每页数据记录条数的范围),但是需要登录才可以进行url地址的访问,就要使用cookie模拟登录。
(2)下面分析有关登录信息的cookie,我使用的是chrome,点击如图位置,会看到此网站的cookie,(如果已经访问了一段时间了,可以清除所有cookie然后重新登录再访问,否则可能会有很多的cookie,分析起来不方便),由于只有5个cookie,直接加上就可以访问了
WebMagic 0.7.3更新内容
本次更新增加了Downloader模块的一些功能。
#609 修复HttpRequestBody没有默认构造函数导致无法反序列化的bug。
#631 HttpRequestBody的静态构造函数不再抛出UnsupportedEncodingException受检异常。
#571 Page对象增加bytes属性,用于获取二进制数据。下载纯二进制页面时,请设置request.setBinarayContent(true),这样对于二进制内容不会尝试转换为String,减小开销。
#629 在HttpUriRequestConverter中会自动对一些导致URI异常的字符进行转移或过滤。
#610 自动识别编码时,可以识别Content-Type中charset为大写的情况。
#627 支持为Request单独设置页面编码,兼容同一站点多种编码方式的情况。
#613 Page对象增加charset属性,其值为request/site中设置的charset,或者为自动检测的charset(未定义时)。
#606 升级jsonpath到2.4.0
∨ 展开
 Kate高级文本编辑器
Kate高级文本编辑器 核桃编程
核桃编程 Thonny Python编程工具
Thonny Python编程工具 Notepad++ 64位中文版
Notepad++ 64位中文版 GitHub Desktop最新版2024
GitHub Desktop最新版2024 Apipost测试
Apipost测试 Wordpress中文免费
Wordpress中文免费 DevEco Studio
DevEco Studio OtoStudio自主编程
OtoStudio自主编程 ADT Plugin for Eclipse最新版
ADT Plugin for Eclipse最新版 Lua for Windws
Lua for Windws RubyInstaller for Windows
RubyInstaller for Windows AVG MAKER DS 游戏制作工具
AVG MAKER DS 游戏制作工具 Delta WPLSoft软件
Delta WPLSoft软件 ResEdit资源编辑器
ResEdit资源编辑器 QXmlEdit
QXmlEdit VbsEdit
VbsEdit Visual studio code Mac版
Visual studio code Mac版 Visual Studio Code 64位编辑器
Visual Studio Code 64位编辑器 蓝牛源码管理助手
蓝牛源码管理助手






 javax.servlet.jsp maven文件
javax.servlet.jsp maven文件 Java SE Development Kit 8.0
Java SE Development Kit 8.0 Java Runtime Development
Java Runtime Development Java Runtime Environment 1.7
Java Runtime Environment 1.7 Eclipse IDE for Java EE Developers
Eclipse IDE for Java EE Developers Eclipse IDE for Java Developers
Eclipse IDE for Java Developers JavaScript权威指南
JavaScript权威指南 TaskBuilder专业版 1.3.30 官方最新版
TaskBuilder专业版 1.3.30 官方最新版 Prepros Windows版 7.8.5 官方免费版
Prepros Windows版 7.8.5 官方免费版 Sublime Text4 文本编辑器最新版 4.0.4143 绿色汉化版
Sublime Text4 文本编辑器最新版 4.0.4143 绿色汉化版 HBuilderX编辑器 3.6.14.20221215 官方版
HBuilderX编辑器 3.6.14.20221215 官方版 JetBrains WebStorm 2022 2022.2 官方版
JetBrains WebStorm 2022 2022.2 官方版 JetBrains Rider 2022 2022.2 官方版
JetBrains Rider 2022 2022.2 官方版