
Capture Text是一款文字识别软件。能够将所抓取的文本或者图像文件转化为可以编辑的文字。
Capture Text使用说明:
Capture Text为什么有些网页和PDF无法提取文字?
两种情况不一样,不能提取网页文字是因为在制作网页编写代码时,禁用了复制功能,而PDF文件分两种情况,一种是在制作PDF文件时安全设置禁止复制拷贝,另外一种情况是PDF文件本身是使用图片文件制作的,文字以图片的形式存在,自然不能单独提取。
对于PDF文件,有安全设置的可以使用PDF Password Remover 或其他破解软件,解除安全设置后查看文件是否是非图片的,如果是,可以复制文字使用,如果是图片转化的,需要使用文字识别软件,尚书不错,但是需要图片的分辨率达到300dbi或以上,效果很好。
PDF文件有两种制作方式,一种是源文件是图片的,一种是使用办公软件或使用其他软件转化生成的,通常在Adobe Acrobat软件中未作安全设置的,可以提取非图片转换的文字,如果要是图片转化的,可以把其中的图片取出来(拷屏或使用软件提取图片),再使用尚书或其他文字识别软件进行识别后使用.
Capture Text详细使用截图:
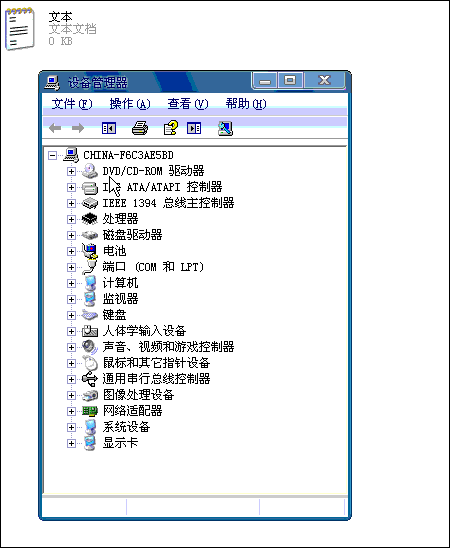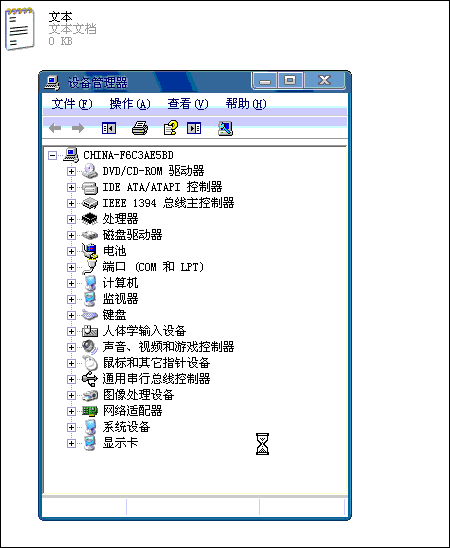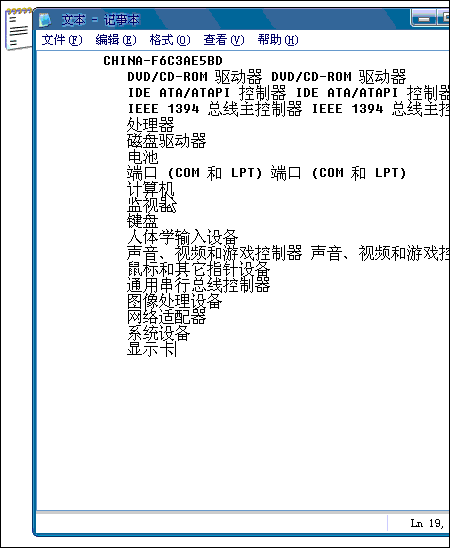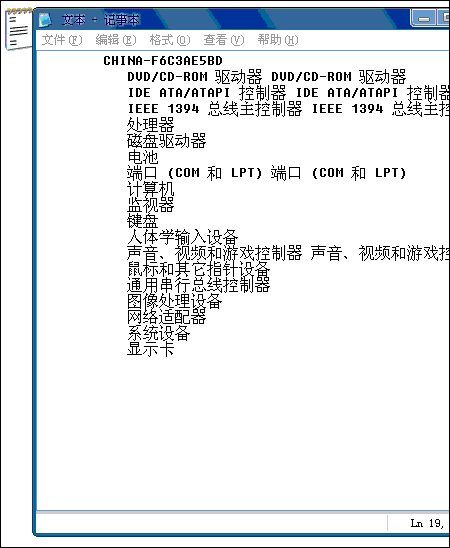
∨ 展开


 WPS Office 2023 教育版
WPS Office 2023 教育版 Typora windows安装
Typora windows安装 WPS Office 2019专业增强版
WPS Office 2019专业增强版 Microsoft Office软件
Microsoft Office软件 Microsoft Office专业增强版
Microsoft Office专业增强版 Microsoft Office2024
Microsoft Office2024 Rogabet Notepad老罗笔记
Rogabet Notepad老罗笔记 幂果OCR文字识别2024
幂果OCR文字识别2024 金山协作
金山协作 onlyoffice电脑版
onlyoffice电脑版 鱼鱼多媒体日记本
鱼鱼多媒体日记本 论文抽屉免费版
论文抽屉免费版 牛牛排版4.0
牛牛排版4.0 蓝牛复制粘贴助手
蓝牛复制粘贴助手 SushiHelper最新版
SushiHelper最新版 Skylark编辑器
Skylark编辑器 防和谐文字处理器电脑版
防和谐文字处理器电脑版 梵语巴利语输入法
梵语巴利语输入法 快贴Mac版
快贴Mac版 快贴云剪贴板
快贴云剪贴板






 OCR文字识别软件
OCR文字识别软件 PandaOCR文字识别
PandaOCR文字识别 天若OCR文字识别本地版
天若OCR文字识别本地版 万兴PDF软件OCR组件离线安装包国际版
万兴PDF软件OCR组件离线安装包国际版 闪电OCR图片文字识别软件
闪电OCR图片文字识别软件 PearOcr
PearOcr EasyScreenOCR
EasyScreenOCR PandaOCR破解
PandaOCR破解 jpg转pdf转换器
jpg转pdf转换器 EXE转JPG文件格式转换器
EXE转JPG文件格式转换器 raw转jpg软件
raw转jpg软件 cr2转jpg软件
cr2转jpg软件 Weeny Free PDF to Image Converter(pdf转换jpg)
Weeny Free PDF to Image Converter(pdf转换jpg) dwg转jpg软件(DWG to Raster Image Converter MX)
dwg转jpg软件(DWG to Raster Image Converter MX) JPEG to PDF(JPG转换成PDF工具)
JPEG to PDF(JPG转换成PDF工具) 捷速OCR文字识别软件
捷速OCR文字识别软件 云脉OCR文字识别软件
云脉OCR文字识别软件 尚书七号(文字识别软件)
尚书七号(文字识别软件) 汉王ocr文字识别软件
汉王ocr文字识别软件 ABBYY FineReader 14破解
ABBYY FineReader 14破解 文通TH-OCR
文通TH-OCR 清华紫光OCR(TH-OCR)
清华紫光OCR(TH-OCR) 赛酷ocr(OCR识别)
赛酷ocr(OCR识别) 思源笔记Mac版 2.9.9 官方最新版
思源笔记Mac版 2.9.9 官方最新版 腾讯文档电脑版 3.1.1 官方最新版
腾讯文档电脑版 3.1.1 官方最新版 子魚笔记Mac版 0.64.0 官方正式版
子魚笔记Mac版 0.64.0 官方正式版 黑曜石笔记软件 1.3.7 绿色中文版
黑曜石笔记软件 1.3.7 绿色中文版 橙瓜码字电脑版 3.0.7 最新版
橙瓜码字电脑版 3.0.7 最新版